Static or Contextual Embeddings
Determine whether your use case requires static embeddings (which remain the same regardless of context) or contextual embeddings (which vary based on surrounding content and produces different vectors for same work based on its context within a sentence.
Static Embedding
Static embeddings assign a fixed vector to each word, independent of its context or sequence in which the word appears.
Embedding Models: Word2Vec, GloVe, Doc2Vec, TF-IDF, etc.
Example:
| User Query | Knowledge Base |
|---|---|
| “I need help with my account settings.” | Knowledge Base 1: “Settings for your account are currently unavailable.” |
In this example, the words "account" and "settings" would have same vector representations in both the user query and knowledge base1, regardless of its specific context.
Techniques like Word2Vec, GloVe, Doc2Vec (dense vector-based), and TF-IDF (keyword/sparse vector-based) enable the system to find relevant results based on the cosine similarity of these vectors.
Limitations:
- Polysemy Issue: The word “account” may have multiple meanings (e.g., a social media account or financial loan account), leading to confusion since it shares the same vector.
- Context Insensitivity: The static embeddings cannot differentiate between various issues related to account settings. For instance, they cannot specify whether the settings are unavailable due to technical problems, user permissions, or other reasons.
Contextual Embedding
Contextual embeddings generate vectors that vary based on the surrounding text, capturing bidirectional or focused context.
- Bidirectional:This approach captures context from both the left and right sides of a word within a sentence, resulting in a comprehensive understanding of the entire sentence.
- Focused Context: This method is specifically tailored for grasping context in shorter text segments, such as sentences or paragraphs.
Embedding Models: BERT, RoBERTa, all-MiniLM-L6-v2, SBERT, ColBERT, etc.
Example:
| User Query | Knowledge Base |
|---|---|
| “I need help with my account settings.” |
Knowledge Base 1: “Settings for your account are currently unavailable.” Knowledge Base 2: “Unable to update settings due to insufficient permissions.” Knowledge Base 3: “Settings change failed due to system error.” Knowledge Base 4: “User cannot access account settings page.” |
Models like BERT, RoBERTa, all-MiniLM-L6-v2, and SBERT (a masked language model), as well as Paraphrase-MPNet-Base-v2 (a permutated language model), effectively understand context, linking phrases like “help with my account settings” to related issues such as “unable to update settings” and “cannot access settings page.” This makes them excellent choices for the retrieval process.
ColBERT (Contextualized Late Interaction over BERT) utilizes BM25 for initial document retrieval and then employs BERT-based contextual embeddings for detailed re-ranking, optimizing both efficiency and contextual accuracy in information retrieval tasks.
Limitations:
- Context Limitation: The Masked and Permuted Language Model excels at understanding context within a specific text span, such as a sentence or paragraph. However, it cannot generate text or perform tasks beyond simply understanding and retrieving relevant documents.
- GPT (Generative Pre-trained Transformer) Embedding: GPT embedding models utilize a method called "transformer embeddings," which captures not only the individual meanings of words but also the context in which they occur. The GPT architecture processes a sequence of words (or tokens) through several layers of transformer blocks. Each block transforms the input into a new sequence of vectors that reflect both the meanings of the words and their relationships with one another. This makes GPT embeddings much more dynamic and context-aware compared to traditional word embeddings.
Unidirectional: GPT embeddings only consider the context from the left side, they build the understanding sequentially as they generate text.
Broad Context: They can maintain coherence over longer text sequences, which makes them particularly effective for producing extended passages of text.
Embedding Models: GTR-T5, text-embedding-3-large, google-gecko-text-embedding, amazon-titan, etc.
Example:
| User Query | Knowledge Base |
|---|---|
| “I need help with my account settings.” |
Knowledge Base 1: “Settings for your account are currently unavailable.” Knowledge Base 2: “Unable to update settings due to insufficient permissions.” Knowledge Base 3: “Settings change failed due to system error.” Knowledge Base 4: “User cannot access account settings page.” Knowledge Base 5: “Please ensure your account is verified to access settings options.” |
Generative-based embeddings: Good for the generation step of RAG. They understand that phrases like “Settings for your account are currently unavailable.” and “User cannot access account settings page.” They facilitate generating responses that are contextually relevant and broader context for example “Please ensure your account is verified to access settings options.”
Limitations:
- GPT embeddings may struggle with generating accurate responses for highly specialized or niche topics due to limited exposure during training.
- GPT tend to require more computational resources compared to purely contextual models like BERT.
General vs. Domain-Specific Models
For your use case choose if you need a general-purpose model that can handle a wide range of topics or a domain-specific model that is tailored for a particular field or industry.
2.1 General vs. Domain-Specific Embedding Models
| When to Use Generic Embedding Models | When to Use Domain-Specific Embedding Models |
|---|---|
|
|
Exploring Generic and Domain-Specific Embedding Models
| Generic Embedding Models | Domain-Specific Embedding Models |
|---|---|
|
|
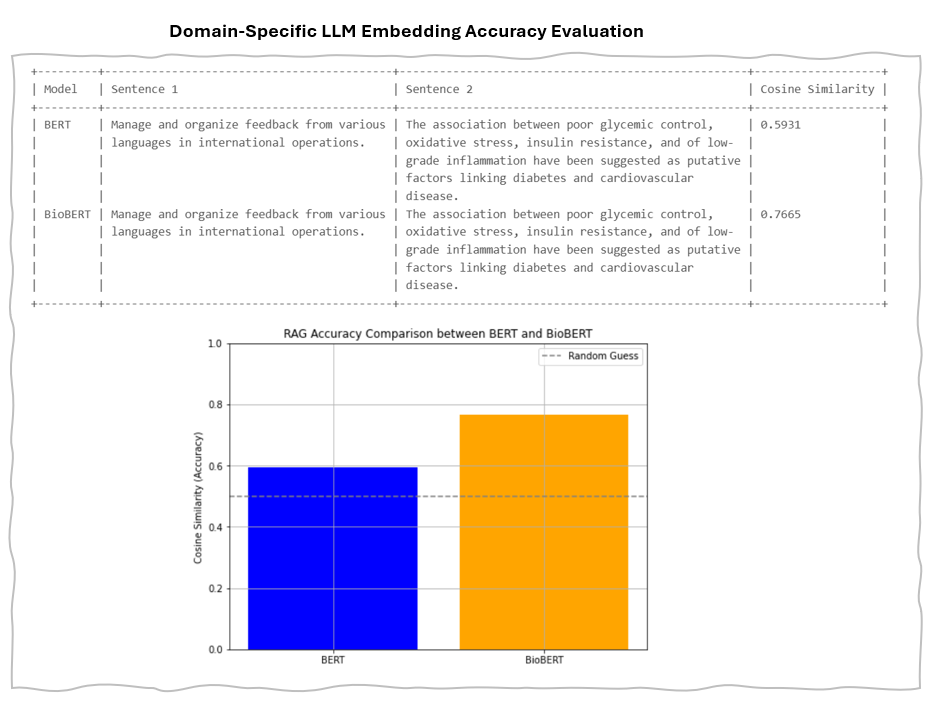
Evaluating Accuracy of Domain-Specific Models
Compare BERT and BioBERT by creating embeddings for two sentences and measuring cosine similarity.
Example of Evaluating Accuracy of BERT and BioBERT embedding
Example Result of Evaluating Accuracy of BERT and BioBERT


Choosing Between Open-Source and Closed-Source Embedding Models: A Practical Guide
Select between open-source models (e.g., evaluated in the Massive Text Embedding Benchmark) or closed-source models with proprietary benefits.
Open-Source Embedding Models
- Local Accessibility: These models are easier to implement and run on your cloud or local storage.
- Cost-Effective: Utilizing them locally is free, and they can be more affordable than commercial options for paid inference.
- Data Privacy: Ideal for scenarios where you want to keep your data private and avoid sharing it with external APIs.
- Control Over Processing: They provide greater flexibility and control over your search pipeline and data handling.
- Local Data Utilization: Particularly beneficial when you have substantial local datasets that you wish to analyse.
| When to Use | When Not to Use |
|---|---|
|
|
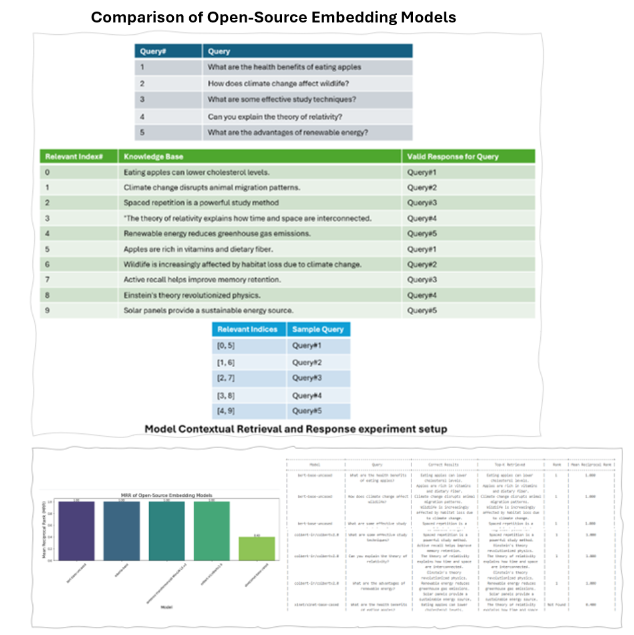
Comparison of Open-Source Embedding Models Using Mean Reciprocal Rank (MRR)
3.1.2 Analysis Result
Closed-Source Embedding Models
- High Inference Speed : These models typically offer very fast inference times, although costs can accumulate with each token processed.
- Optimized Performance : They often excel in specific applications, such as multilingual tasks or generating instruction-based embeddings.
| When to Use | When Not to Use |
|---|---|
|
|
Additional Key Considerations
The MTEB (Model and Text Embedding Benchmark) Leaderboard is an excellent resource for exploring the current landscape of both proprietary and open-source text embedding models, particularly for Retrieval-Augmented Generation (RAG) applications. It provides a comprehensive overview of each model, detailing important metrics such as model size, memory requirements, embedding dimensions, maximum token capacity, and performance scores across various tasks, including retrieval, summarization, clustering, reranking, and classification.
- Max Tokens: Consider the maximum number of tokens the model can process, which can affect performance and relevance.
Maximum token indicates the upper limit of tokens that can be processed into a single embedding. In the context of Retrieval-Augmented Generation (RAG), an ideal chunk size is usually around a single paragraph or less, typically consisting of about 100 tokens. For most applications, models with a maximum token capacity of 512 are more than sufficient. However, there are certain situations where embedding longer texts may be necessary, which would require models with a larger context window to effectively handle the additional tokens. This consideration is crucial for optimizing the performance of RAG systems.
- Retrieval Average: Look at how effectively the model retrieves relevant information, as this impacts overall quality.
Retrieval Average metric reflects the average Normalized Discounted Cumulative Gain (NDCG) at rank 10 across multiple datasets. NDCG is widely used to evaluate the effectiveness of retrieval systems. A higher NDCG score indicates that the embedding model excels at prioritizing relevant items at the top of the retrieved results. This is particularly important in Retrieval-Augmented Generation (RAG) applications, where the quality of the retrieved information significantly impacts the overall performance and relevance of the generated responses.
- Embedding Dimensionality: Assess the dimensionality of the embeddings, as higher dimensions can capture more detail but may also increase complexity.
Embedding Dimensions refers to the length of the embedding vector generated by the model. Smaller embedding dimensions can lead to faster inference and are more efficient in terms of storage, making them ideal for quick retrieval in RAG applications. However, they may sacrifice some accuracy in semantic representation. In contrast, larger embedding dimensions allow for greater expressiveness, enabling the model to better capture intricate relationships and patterns within the data. This, however, comes at the cost of slower search times and increased memory requirements. The goal is to find an optimal balance between capturing the complexity of the data and maintaining operational efficiency, especially when determining chunk sizes for effective embedding in RAG tasks.
- Model Size: Take into account the size of the model, which influences both computational resources and deployment capabilities.
This refers to the size of the embedding model measured in gigabytes (GB), which provides insight into the computational resources needed to operate the model. While larger models typically offer improved retrieval performance, it's crucial to recognize that increased model size can also lead to higher latency. This latency-performance trade-off is particularly significant in production environments, where response time is critical for effective Retrieval-Augmented Generation (RAG) applications. Balancing model size and latency is essential for optimizing both performance and user experience.